How to size & scale your Laravel Queues
Published on October 31, 2018 by Mattias Geniar

Laravel offers a convenient way to create asynchronous background tasks using its queues. We utilize those heavily at Oh Dear! for all our monitoring jobs and in this post we'll share some of our lessons learned and what we consider to be best practices.
Getting started with queues #
The most basic example you'll find is similar to this, where you push a job onto a queue and a worker will pick it up for processing.
Job::dispatch()->onQueue('general');
Whatever job you wanted to queue has now been pushed to a queue named general. Every other job you add to that queue will be added (FIFO) and processed in that order.
While a great way to start, you quickly run into a queue that potentially looks like this.
\_ job #1: 12s \_ job #2: 3s \_ job #3: 3min \_ job #4: 32min \_ job #5: 5s
Assuming you have one worker to pick jobs from this queue, job 5 would have to wait 2115 seconds for all former jobs to be completed before it gets its turn.
Adding multiple workers to that queue speeds things up, but still has the potential for blocking, long running tasks. Ideally, you'd want to split that up further.
Fast vs. Slow jobs #
One strategy we first used was to make a generic seperation between fast and slow jobs.
If you remember the purpose of Oh Dear! (monitoring sites, crawling them, reporting page errors etc.), it quickly becomes apparent that we are heavily dependent on 3rd parties.
If the site we're monitoring is quick to crawl, it might take only a few minutes. If it's a slow site (on which we have to apply rate limiting), it might take a very long time but consume few resources along the way.
Slow to us means the remote side is slow. It also means we're wasting CPU cycles just waiting for the other end to respond. We could easily spin up more workers and do more in parallel, since the load is negligable on our end.
At first, we ended with a queueing system similar to this.
- fast worker \_ worker #1 \_ worker #2 - slow worker \_ worker #1 \_ worker #2 \_ worker #3 \_ worker #4
The result was that the fast queue consumed most of the CPU & memory on our end: it quickly burned through its queue, performing all the "fast" tasks (checking uptime, certificate checks etc.).
The slow queue was running more consumers (aka workers), because we were constrained by the remote end, not ours. This meant we could easily run more of those.
While this worked for the first few weeks in beta, as our customer base grew, this also posed a few problems: while the fast queue was generally pretty fast, we were pushing a lot of different workloads on there.
UptimeChecker::dispatch()->onQueue('fast'); CertificateChecker::dispatch()->onQueue('fast'); ...
A certificate check takes a bit longer to complete than most uptime checks. And, arguably, the uptime check is more important than the certificate check.
We needed a better solution.
Single-purpose queues #
It didn't take long for us to create specific queues for each job "type" we were launching. We're now in a setup where each check performed lives on its own queue. This allows us a great deal of flexibility in terms of sizing and scaling them.
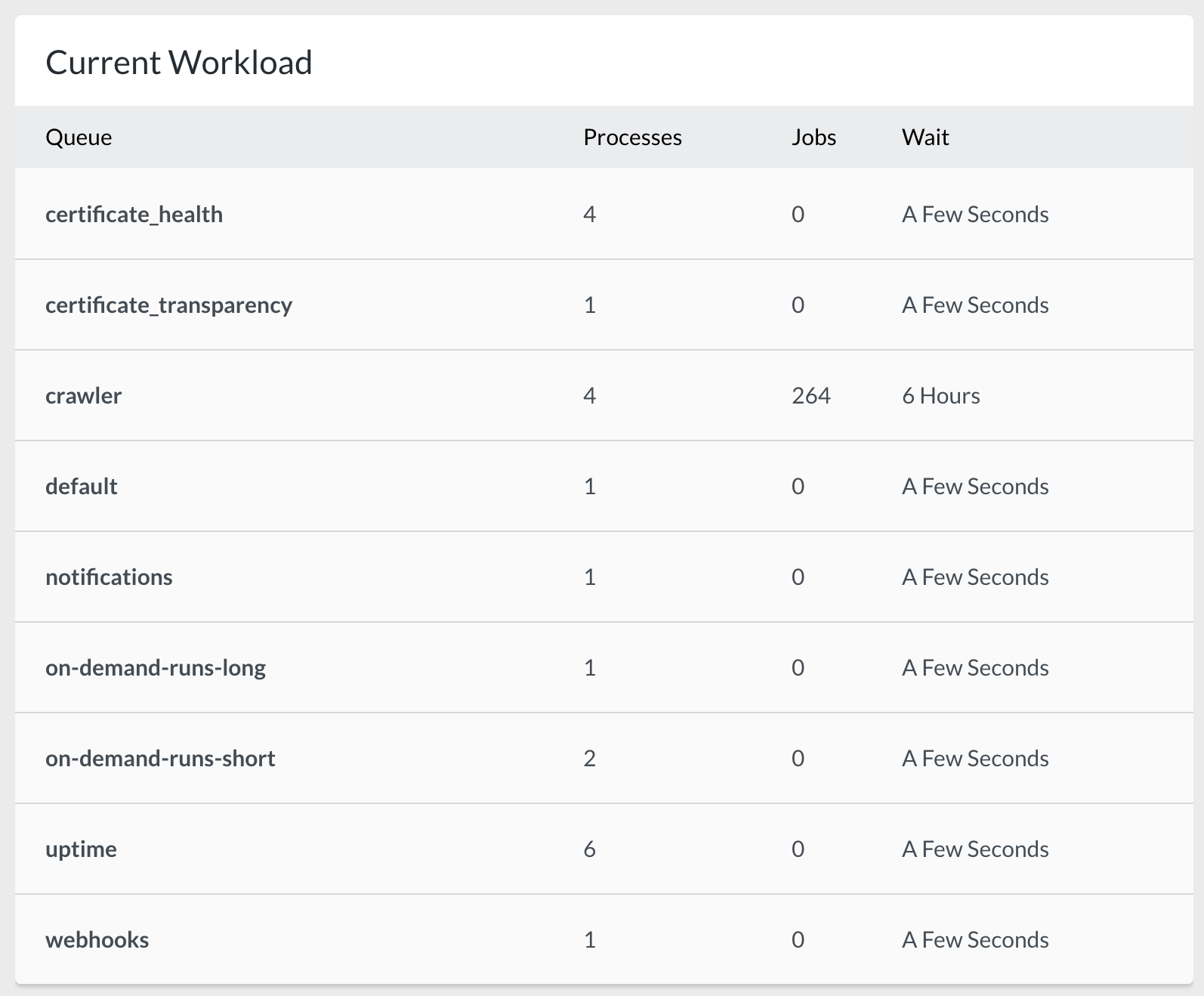
We run a few very specific job queues too. Our main application runs on the following queues.
- certificate_health - certificate_transparency - crawler - uptime
These queues run our monitoring checks for all our sites. On top of those, we have assisting queues.
- default - notifications - webhooks
The notifications and webhooks are pretty self-explanatory: they run all our notifications (Slack/Discord/Nexmo/...) and perform the webhook calls to 3rd party endpoints.
The default queue is used for small, one-off jobs that are just too small for their own queue (like sending mails like our monthly uptime reporting).
But then there are some special queues, too.
On-demand queues for a better UX #
When you add a site to be monitored, your initial experience looks like this.

That's the user experience we want: immediate feedback and the feeling of responsiveness when you add a site. The certificate & uptime checks happen near-instantly, the broken links checking takes a bit longer as the site needs to be crawled.
To make that work, we push the sites that have just been added to an empty queue with a custom set of workers that can immediately pick them up.
UptimeChecker::dispatch()->onQueue('on-demand-runs-short'); CertificateChecker::dispatch()->onQueue('on-demand-runs-short'); CrawlerChecker::dispatch()->onQueue('on-demand-runs-long')
We didn't take this approach at first, which meant our queues ended up like this.
- uptime worker \_ job #1 \_ job #2 \_ job #3 <-- the uptime check for the site that was just added - certificate worker \_ job #1 \_ job #2 \_ job #3 \_ job #4 \_ job #5 <-- the certificate check for the site that was just added
If you added a new site, your were added to the back of the queue and had to wait for all other jobs to complete first. The initial user experience gave the impression we were slow & unresponsive, because it took too long for feedback in the UI.
We first tried to get away with adding them to the front of the queue instead of at the back, but that didn't entirely work either: if, for some reason, the uptime check took a few seconds to finish its current job, we still had to wait for our new priority job to be picked up.
And since we monitor & crawl sites we don't control, we have no idea how long each check might take. We need to assume the worst case & plan for that.
The on-demand runs pick up those sites that have just been added and those jobs that the user requested to be run on-demand (which you can trigger either from your Oh Dear! dashboard or through the API). If we ever reach the point where we detect saturation (ie: the queue never empties), we will have to split the queue again to separate the initial runs vs. the on-demand runs.
If a worker stalls or a queue backs up you want to hear about it before users do. Oh Dear's application health monitoring watches exactly that.
In conclusion #
We iterated over a few versions but have ultimately settled on this setup which works great for us. Use cases may vary, but our key take-aways are:
- A queue per "type" of job you have
- Size the amount of workers for slow vs. fast workloads
- A separate queue for tasks that need to give quick UI/UX feedback to the user
Related infra work: moving from Laravel Echo Server to Laravel WebSockets.
If you've got any more Laravel queue related tips, we would love to hear about them!