SQL performance: analysing & fixing slow queries (part 2)
Published on October 6, 2025 by Mattias Geniar

This is part 2 of a 3-part series on SQL performance improvements.
A few weeks ago, we massively improved the performance of the dashboard & website by optimizing some of our SQL queries. In this post, we'll dive deeper into the optimisations of queries with indexes.
Table of contents:
- Ways to improve database performance
- How database indexes work
- Let MySQL explain why a query is slow
- Different EXPLAIN output
- Adding indexes
- Multiple indexes vs. composite indexes
- The order of the index vs. the order of the WHERE statement
- NULL values in indexes
- What performance gains to expect
- Random trivia on indexes
- The AI way: how LLMs can help
Let's go!
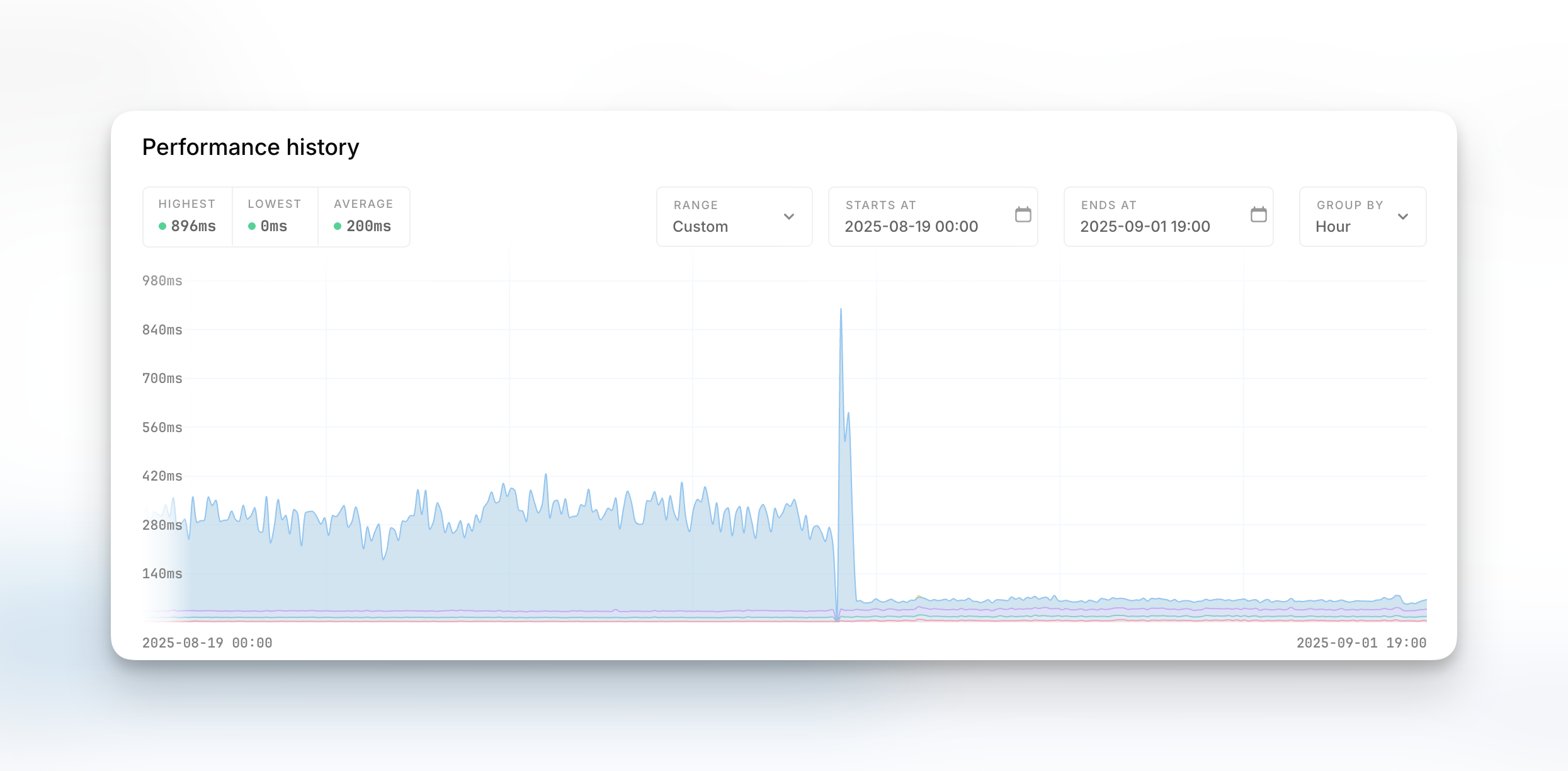
What these results look like #
As a reminder, this is the resulting performance gain for the dashboard & some of our internal APIs:

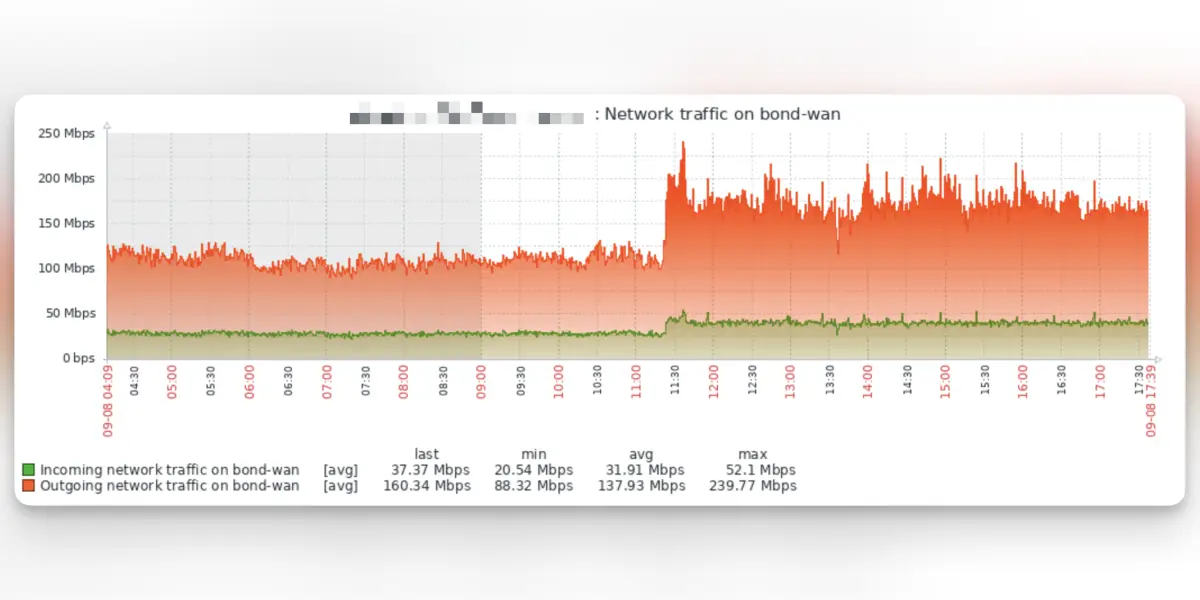
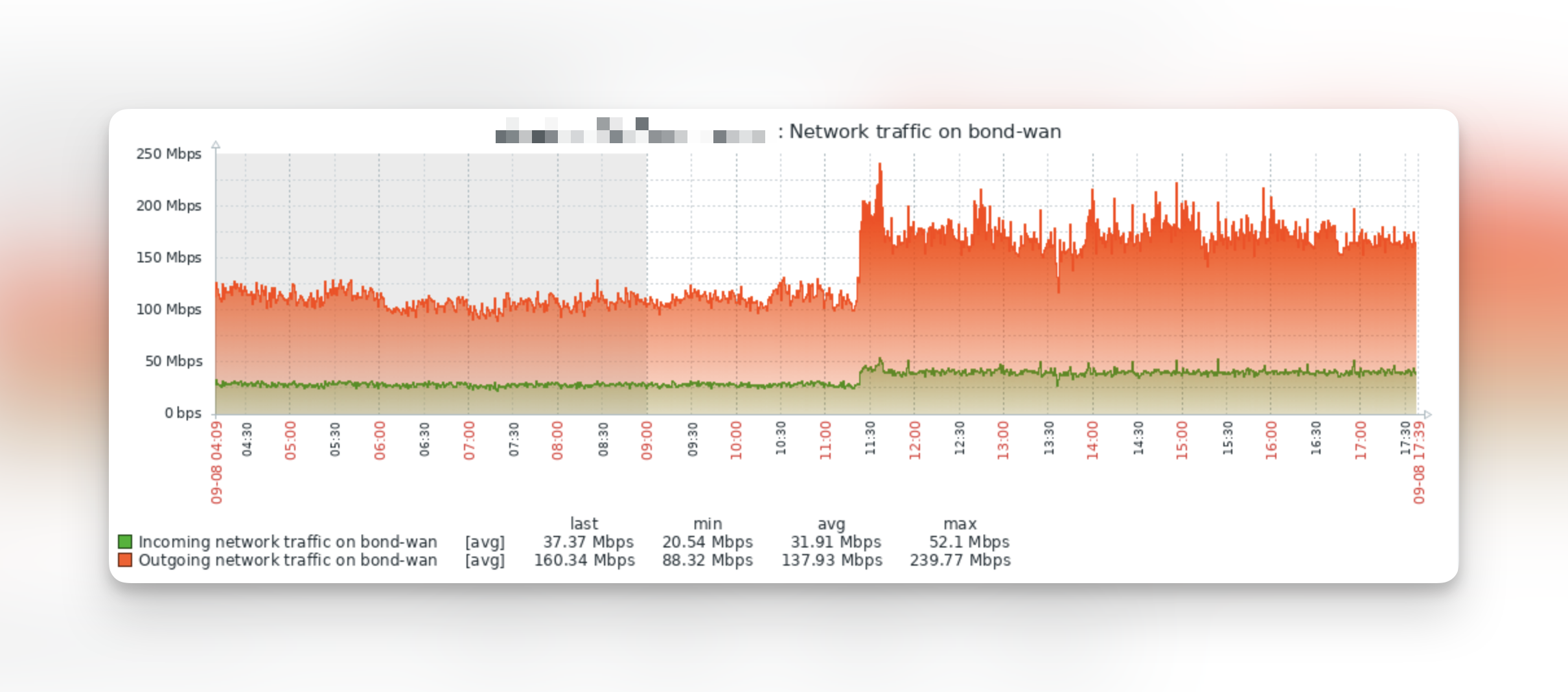
These graphs come from the Oh Dear uptime monitoring we perform. Behind the scenes, we also use Zabbix for low-level server monitoring, where we get extra insights into the performance of our servers.
The optimisations have lead to an increase in network bandwidth between our SQL server & the rest of our infrastructure. Normally an increase like this would be cause for concern, but in our scenario it's because we're now able to perform all checks faster and complete our queues at a much faster pace, so that we're able to utilize the network bandwidth more.
As a result of our improvements, we were able to almost double the SELECT's (green line) we're able to do concurrently.
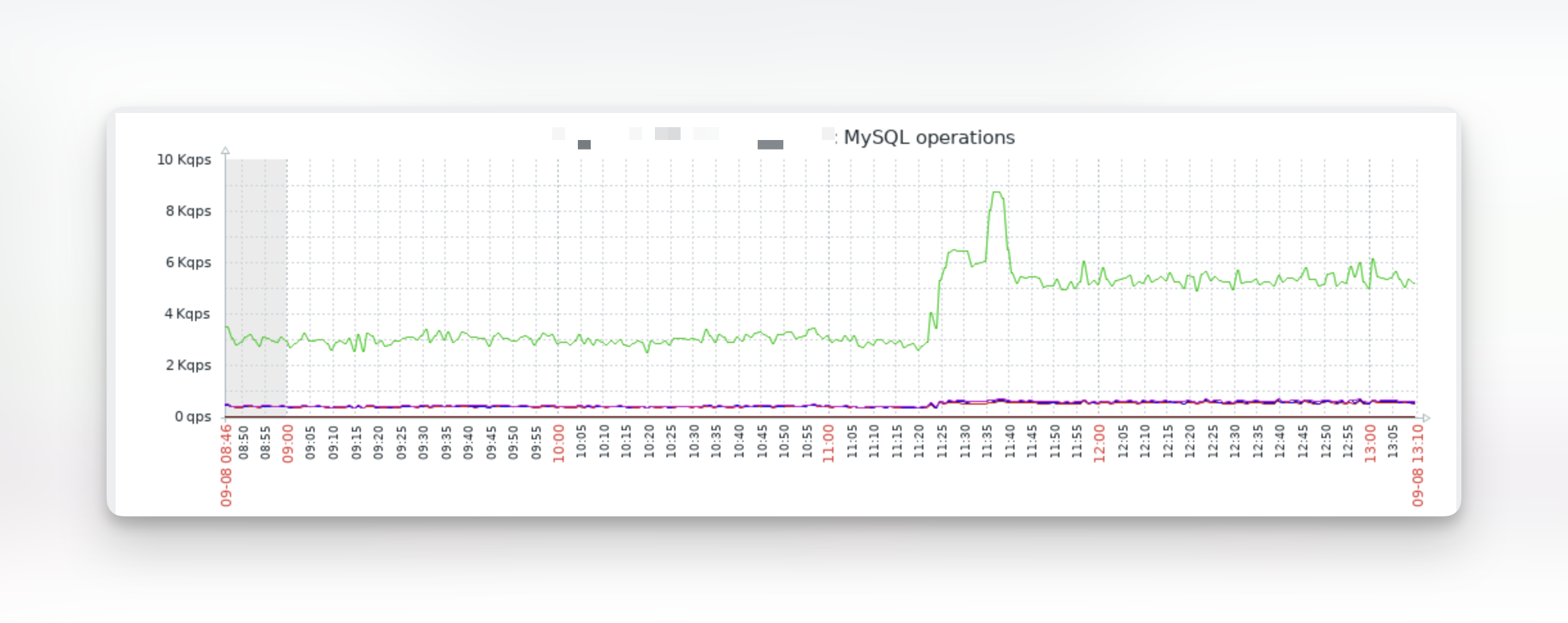
This also gives us a bit of context: at a constant load of ~6,000 SELECT's per second, around 1,000 INSERT's, another 1,000 UPDATE's and ~600 DELETE's per second, we've got ourselves a busy system.
So then, what did we do to get these numbers?
Ways to improve database performance #
In general, speeding up SQL queries can be done in 4 main ways;
- Avoiding the query altogether (resolving N+1 loops, introducing caching, etc.)
- Rewriting the query to be more performant (different joins, fewer subqueries, etc)
- Get faster hardware
- Adding indexes to the table to speed up data lookups
This post focusses mostly on the last point: the indexes, the hidden weapon of any database system.
How database indexes work #
For clarity, we run on MySQL 8.0, what we're explaining in this post is tested and applied on our systems, and should work on PostgreSQL and even SQLite - although the output of the EXPLAIN queries lower in this article will vary.
Imagine a table with 100,000,000 rows of data and multiple columns. If you ask your database to perform the following query:
mysql> SELECT * FROM big_table WHERE user_id = 1 AND deleted_at IS NOT NULL;
Without indexes, the database has to scan the entire table for rows that match your criteria. With indexes, it has a general idea of where the records you'll be asking might be. It's the difference between walking across a country with or without a map. You can get there, but it'll be a lot more efficient with that map.
When it comes to using indexes, you need to have a good idea on what data you want to filter on. Generally, that's everything in your WHERE clause. That's where the indexes come in.
In our example above, we're filtering data on both user_id and deleted_at, ideally we have an index that combines both of those data points for faster lookups, although even one index (say on the user_id column) would already make big differences.
There's a few gotcha's with that query straight-away (hint: nullable values can be tricky) which we'll cover deeper down.
Let MySQL explain why the query is slow #
In our previous post, we explained the techniques to identify which queries need improving. If you've followed along, you might now have a list of queries that have been identified as slow. Now, it's time to analyse them. That's where MySQL's EXPLAIN keyword comes in.
Take your slow query, add in the keyword EXPLAIN just before your own query, and let MySQL tell you what it did during execution.
mysql> EXPLAIN SELECT * FROM ...
The output can be something like this:
id: 1
select_type: SIMPLE
table: <your table-name>
partitions: NULL
type: ref
possible_keys: <table-name>_created_at_index
key: <table-name>_created_at_index
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: Using filesort
To start, the most important fields are:
- possible_keys: if indexes already exist in your table, these are the ones that are under consideration for executing this query
- key: if there are multiple indexes, this is the one MySQL ended up chosing
- rows: MySQL estimates it will need to examine 1 row to satisfy the WHERE clause
- filtered: 100% of the examined rows are expected to pass the WHERE condition.
- extra: the biggest clue is here
The extra column can contain a lot of value, typically you'll see values like these, sorted by the best possible output (aka the fastest queries) to the slowest.
- The best performance:
- (no extra info) - Optimal: using index efficiently with no additional operations
- Using index - Very fast: query satisfied entirely from index without accessing table data
- Using where; Using index - Fast: filtering done on index data only
- Using index condition - Good: index condition pushdown reduces data transfer
- Moderate performance:
- Using where - Acceptable: additional filtering applied after index lookup
- Distinct - Moderate: removing duplicates, but can use index
- Using index for group-by - Good for GROUP BY: grouping operations done via index
- Performance concerns:
- Using filesort - Slow: sorting requires additional memory/disk operations
- Using temporary - Slow: temporary table needed for complex operations
- Using temporary; Using filesort - Slower: both temporary table creation and sorting required
- The worst performance:
- Using join buffer - Slow: nested loop join without efficient index access
- Using where; Using join buffer - Very slow: inefficient joins with additional filtering
- Range checked for each record - Very slow: MySQL recalculates optimal index for each row
- Full scan on NULL key - Extremely slow: cannot use index due to NULL handling in subqueries
The key principle here is: anything involving filesorts, temporary tables, or full scans without indexes will significantly impact query performance and should be solved.
Different EXPLAIN output #
MySQL has several outputs for an EXPLAIN query, depending on your preferred tooling, these can be useful to you:
-- output in tabular format, the default mysql> EXPLAIN SELECT * FROM ... -- output in JSON, also contains cost calculations -- from the query optimizer mysql> EXPLAIN FORMAT=JSON SELECT * FROM ... -- outputs a visual hierarchy of operations, -- useful with many joins mysql> EXPLAIN FORMAT=TREE SELECT * FROM ... -- performs the actual query and compares -- estimated vs. actual rows mysql> EXPLAIN ANALYSE SELECT * FROM ...
I usually default to just the standard EXPLAIN output.
Adding indexes #
Most slow queries can be solved by adding indexes. This ensures MySQL can find the data efficiently, without having to scan the entire table.
Take the following query for instance:
SELECT * FROM `snooze_history_items` WHERE `snooze_history_items`.`check_id` = 1 AND `ends_at` > '2025-09-13 20:00:00' ORDER BY `ends_at` DESC LIMIT 1
We're querying a pretty big table to get some results. The two WHERE conditions are meant to limit the result, but without indexes, MySQL needs to scan and read the entire table, filter out the requested results, then return them.
To make matters worse, it also needs to then sort the result set in memory, before returning the result.
Both actions - reading the entire table to filter the results and then sorting them - are incredibly CPU intensive. If the query can't be simplified further, it's time to add an index so MySQL can consult its index for the results, efficiently gather only the data it needs, and instantly return it.
mysql> CREATE INDEX idx_check_ends_optimized ON snooze_history_items (check_id, ends_at DESC);
Or in a Laravel migration:
Schema::table('snooze_history_items', function (Blueprint $table) { $table->index(['check_id', 'ends_at'], 'idx_check_ends_optimized'); });
Now when we ask the EXPLAIN output, we'll see:
mysql> EXPLAIN SELECT ... possible_keys: idx_check_ends_optimized key: idx_check_ends_optimized Extra: Using index condition; Backward index scan
This saves a tremendous amount of CPU cycles in MySQL reading all data & sorting the results. At our scale of close to 10k queries/s, this seriously adds up.
Multiple indexes vs. composite indexes #
After a while, you might have multiple indexes on any given table, like these:
KEY `table_user_id` (`user_id`) USING BTREE, KEY `table_user_id_deleted_at` (`user_id`,`deleted_at`) USING BTREE, KEY `table_user_id_deleted_at_client_type` (`user_id`,`deleted_at`,`client_type`) USING BTREE
Written differently, this table has 3 indexes:
- user_id ("user_id_index")
- user_id, deleted_at ("user_id_deleted_at_index")
- user_id, deleted_at, client_type ("user_id_deleted_at_client_type_index")
Indexes are used/read from left-to-right: an index that consists of 3 columns, like our user_id_deleted_at_client_type_index in the example above, can also be used by queries that only search for the left-most column of that index.
If you're performing a query like:
SELECT * FROM users WHERE user_id = 1;
Any of the 3 indexes is capable of supporting this query, because the user_id is the left-most index. This actually makes the first index, user_id_index, obsolete and it can be dropped.
The order of the index vs. the order of the WHERE statement #
Both of the following queries will use the same available index on the user_id, deleted_at fields. The order of the WHERE statements does not matter:
SELECT * FROM big_table WHERE user_id = 1 AND deleted_at IS NOT NULL
and:
SELECT * FROM big_table WHERE deleted_at IS NOT NULL AND user_id = 1
The order of the index, on the other hand, does matter!
When creating indexes, it helps to visualize which data-filter would reduce the result set the most. In our query, if we can filter based on user_id first, we might already limit the scope of our query to 1% of the total table. This filter has the biggest impact. It's also the most likely field to be used in WHERE statements, so can probably be re-used by other queries, it makes sense for both of these reasons to keep user_id the first column in the index.
If we turned the indexes around, like so:
KEY `table_deleted_at_user_id` (`deleted_at`, `user_id`) USING BTREE,
We'd now have an index that starts with the deleted_at column, followed by the user_id column. Now, any query that filters only on the user_id can no longer use this index and will have to fall back to a full table scan, even though it's part of another index.
NULL values in indexes #
Some fields in your table might be nullable. A good example is usually a deleted_at soft-delete timestamp. It's only filled in with a date if a record is actually soft-deleted.
The main gotcha with nullable columns in MySQL indexes is that NULL values are indexed, but they can cause performance issues in your queries:
-- This CAN use the index WHERE deleted_at IS NULL WHERE deleted_at IS NOT NULL -- These too, for either range or equality checks WHERE deleted_at = '2025-10-06' WHERE deleted_at >= '2025-10-06' WHERE deleted_at < '2025-10-06' WHERE deleted_at BETWEEN '2025-01-01' AND '2025-12-31' -- These CANNOT efficiently use the index WHERE deleted_at != '2025-10-06' -- Inequality (requires scanning most of the index, inefficient range scan) WHERE deleted_at <> '2025-10-06' -- Same, requires scanning most of the index WHERE NOT (deleted_at = '2025-10-06') -- NOT conditions also require scanning most of the index here
If you need consistent indexes on datetime fields, you could opt for a default timestamp (ie 1970-01-01) on that column instead and removing the nullable property.
As a rule of thumb, where possible, put nullable columns as the last column in your composite indexes.
What performance gains to expect #
I define a fast query as one that completes under 15-20ms, depending on the size of the output. For single-row queries, it's reasonable to expect a response around 1ms to 2ms. Larger responses (ie many rows) will just take longer to travel over the network as well, let's set that upper bound to somewhere around 20ms.
Take the following example for instance:
SELECT * FROM big_table WHERE user_id = 1 LIMIT 10
The performance results are:
- Without an index on
user_id: 32ms - With an index on
user_id: 3ms
That's a straight up 10x faster query, just with an index.
The results are a little more extreme with bigger tables or more complex queries, in our environment where we might have big queries with joins, subqueries & lots of WHERE conditions, we've seen improvements from > 5s down to < 50ms, that's an almost 100x faster query.
Random trivia on indexes #
A few notes & thoughts on indexes in general;
- They usually only matter for bigger tables, on very small tables, full scans might actually be faster than index lookups.
- More indexes = slower write performance, so slower
INSERT,UPDATEandDELETEqueries. This can significantly slowdown the write performance, a table with 3+ indexes can see slower write performance by up to 20% and more. The larger (more columns) the index, the slower writes will become. Another reason to use a single, good, composite index vs. overlapping smaller ones. - Most applications benefit from more indexes, they often have a 95% SELECT vs. 5% WRITE ratio on database load anyway.
- Primary keys & foreign keys are automatically indexes as well, but are added as single-column indexes, and may be redundant with composite indexes.
- Indexes consume disk space, but I've never realistically seen this have any noticeable impact.
- Indexes also use RAM, but I've also not seen this become an issue.
- You can always get a bigger and faster database server, often times, this is cheaper than spending weeks optimizing code or queries.
- Using functions in queries means the index won't be used, ie
WHERE YEAR(created_at) = 2025won't use an index on created_at, butWHERE created_at >= '2025-01-01' AND created_at < '2026-01-01'will - Leading wildcard searches break indexes:
WHERE name LIKE '%smith'can't use an index, butWHERE name LIKE 'smith%'can. - In the past 20yrs of managing servers, I've had one weird instance where indexes became corrupt (queries were always slow, regardless of the indexes), where it needed an
OPTIMIZE TABLE <table>to rebuild indexes. Since then, I runOPTIMIZE TABLEquite often when troubleshooting.
Curious to hear trivia you might have on SQL performance that we don't yet know about!
The AI way: how LLMs can help #
When you give your AI of choice enough context, the suggestions can be extremely powerful. You'll need to be diligent in reviewing the response, but if what you're looking for is a good first review of a slow query, this helps:
Below is the EXPLAIN output of a slow query, followed by the result of the query analysis. The table structure is below that. Analyze the query and suggest which indexes to add, clarify why, and show the index creations in the Laravel migration format.
Follow that with;
- The exact
EXPLAIN SELECT ...query - The output of that EXPLAIN
- The output of
SHOW CREATE TABLE <tablename>
This gives the LLM the query that's slow, what the query planner did to execute it as well as the full table structure - including current indexes - to work with.
You should, however, review the suggestions and see if any of the indexes the LLM might suggest already exist or could be part of a composite index you added in earlier, to avoid duplicating indexes.
Next up, automatically detecting performance regressions so they never come back.
Once the slow queries are fixed you want to know if they ever creep back, that is what continuous performance monitoring is for.
Feedback? #
If this article contains any errors or if it should clarify certain sections more, do reach out via either mattias@ohdear.app or ping me via @mattiasgeniar or our @OhDearApp account. Any feedback is appreciated!