Oh Dear's broken links detection works just like our mixed content checks: every site added to Oh Dear automatically has all its pages crawled to report HTTP errors (like missing pages, server side errors or timeouts).
If we find the same broken links in subsequent crawls we won't drown you in notifications, but we'll send you a reminder that there are broken links after 7 days.
Reporting broken links #
Oh Dear will crawl your monitor and all its pages and create a summary for you with all pages that meet these criteria;
- The HTTP status code is not a
HTTP/2xx or HTTP/3xx
- The page took longer than 5 seconds to load
We treat all pages in the HTTP/200 to HTTP/399 range to be OK, as long as they load in less than 5 seconds. Anything that deviates from that pattern will be reported.
Internal vs. external links #
By default we will only report on internal pages of your site that are broken. In other words: pages on the same (sub)domain of your main website.
We can also check for the external pages you link to. If you care about sending your visitors to 3rd party websites, you can check the option to Include external links in the Settings screen. From then on, we'll follow links that move away from your own (sub)domain and check they also respond OK.
This protects you from linking to offline pages & broken or invalid URLs. After all, if you guide your visitors to an external URL, you'd rather have it be a working one - right?
Exclude your own URLs #
Some URLs will trigger a 404 on purpose or might be more difficult to fix in the short-term. To help your notifications, you can ignore particular URL patterns per website in your settings screen per site.
You can add URLs using a simple pattern. Here are some examples.
https://your-domain.com/private/*
https://your-domain.com/forum/admin/*
https://your-domain.com/*/edit
https://external-domain.com/*
*forum*
The example above will ignore any crawl errors on the URLs that start with /private/, /forum/admin/ or that have /edit anywhere in the URL.
We also exclude several particular URLs globally, to avoid making these reports too noisy.
Globally Excluded URLs #
We automatically exclude the following URLs in our reports. These are often used for social media sharing and will trigger false positives.
https://news.ycombinator.com/*
https://www.facebook.com/sharer/sharer.php*
http://www.reddit.com/submit?*
https://github.com/issues?*
https://github.com/pulls?*
https://itunes.apple.com*
https://docs.spatie.be/join*
*/cdn-cgi/l/email-protection*
/cdn-cgi/l/email-protection*
https://*.instagram.com/*
If you've noticed a set of URLs we should globally exclude, please get in touch.
Not all pages will be crawled #
Oh Dear crawls your websites to report broken links and mixed content. In some circumstances, we won't crawl all pages. Here are some things to keep in mind:
- each crawl is limited to 20 minutes (or 5,000 pages, whichever comes first)
- if a page takes more than 5 seconds to load, we assume it is not working
- we only parse the first 512KB of content of any page (uncompressed)
- JavaScript is not rendered
- the check is performed each day (every 24 hours)
- by default, we respect robots.txt (can be configured)
- by default, we do not crawl external links (subdomains are considered external)
Crawl prevented by robots.txt #
If you have a robots.txt page with content similar to this, Oh Dear will not crawl a single page on your site.
User-agent: *
Disallow: /
This content essentially tells robots (search engines like Google/Bing, but also our crawler) to not crawl any page on this site, starting from and including the root page /.
If you have a robots.txt page like this, we will report 0 pages scanned in Oh Dear.
You can tweak which pages we can/can't crawl in your robots.txt though, for more fine-grained controls.
Additionally, we also listen to both the HTML tags as well as the x-robots-tag HTTP header. If we see an HTML tag similar to this, we won't crawl that particular page:
<meta name="robots" content="noindex" />
And here's an example HTTP header that prevents robots from crawling the monitor:
x-robots-tag: noindex
JavaScript initiated content #
Our crawler currently does not parse JavaScript. We fetch the content from your monitor and its pages and look at the raw HTML (DOM) we get back to search for links.
If your HTML is empty because it is dynamically injected with JavaScript during page load, we won't be able to find and crawl any pages.
Rate limits against our crawler #
Webservers can sometimes implement a feature called rate limiting. It reduces the amount of requests a particular IP address or User-Agent can make. Since we crawl websites on a frequent basis, our crawlers are sometimes affected by this.
If we receive an 429 Too Many Requests HTTP status message during our crawls, we'll notify you of this in the detailed view of the report.
To resolve this issue, please allow our IP addresses so we are no longer rate limited or decrease the crawling speed with which we check your site.
Limitations of the crawler & broken links checking #
We have a few limitations in place to help protect your website when we crawl it.
- We crawl at most 5,000 pages per website added in Oh Dear
- Crawls are limited to a 20-minute duration
- We only parse the first 512KB of content of any page (uncompressed)
Whichever limit is hit first (max number of pages or the 20-minute limit) will stop our crawling.
This helps protect your site from infinite page loops or excessive load caused by our crawler.
If your site has more than 5,000 pages, you can add the site multiple times with different starting points. We start crawling based on the URL you enter. For instance, if you add the following 5 URLs, each will start crawling on its own and report broken pages based on that entry point.
- yoursite.tld/en
- yoursite.tld/fr
- yoursite.tld/nl
- yoursite.tld/blog/archive
- yoursite.tld/...
This gives you more control over where we should start crawling and checking for broken pages.
Increase or decrease the crawl speed #
You can change the speed of our crawler, to either crawl faster or slower, depending on your preference. You'll find this in the Settings tab of a broken links or mixed content check.
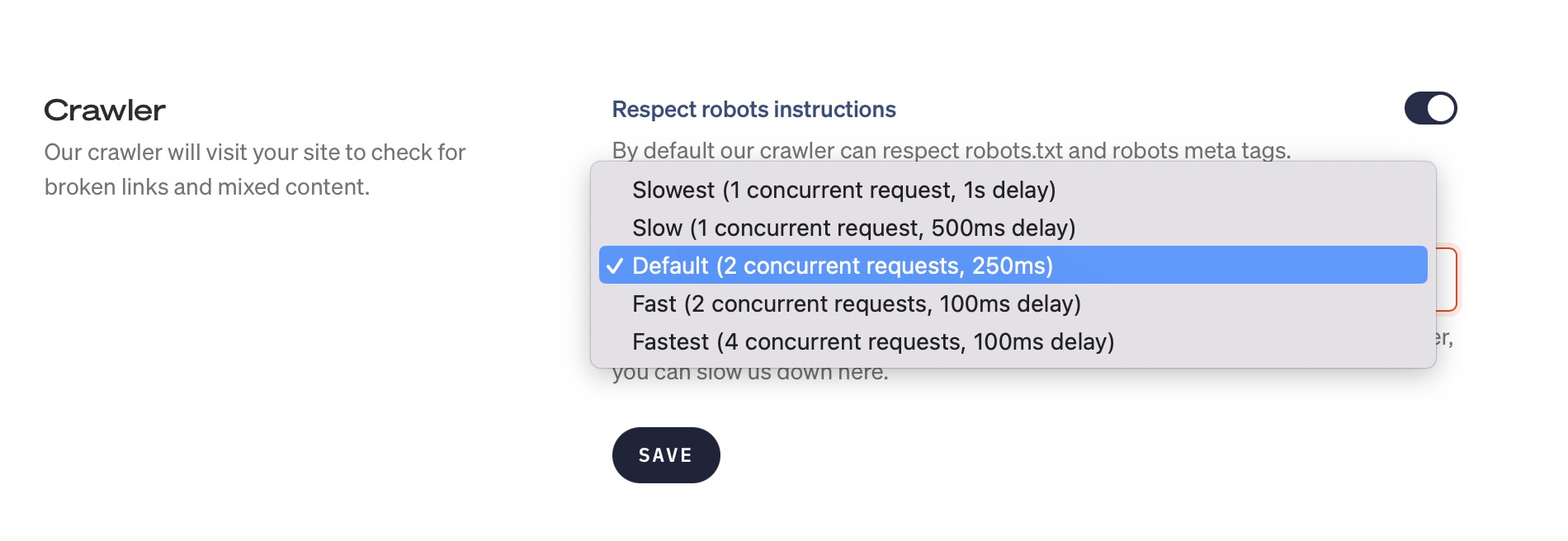
If you notice excessive server load whenever we crawl your site, you may pick a slower crawling preference.
If you hit the 20-minute limit often, you may increase the speed and concurrency, to allow us to crawl more pages in that limit. Please note, your server load will increase as a result, as we're doing more HTTP(s) requests in the same timespan.