Improvements to our status pages as we tackle a DDoS
Published on May 14, 2026 by Mattias Geniar

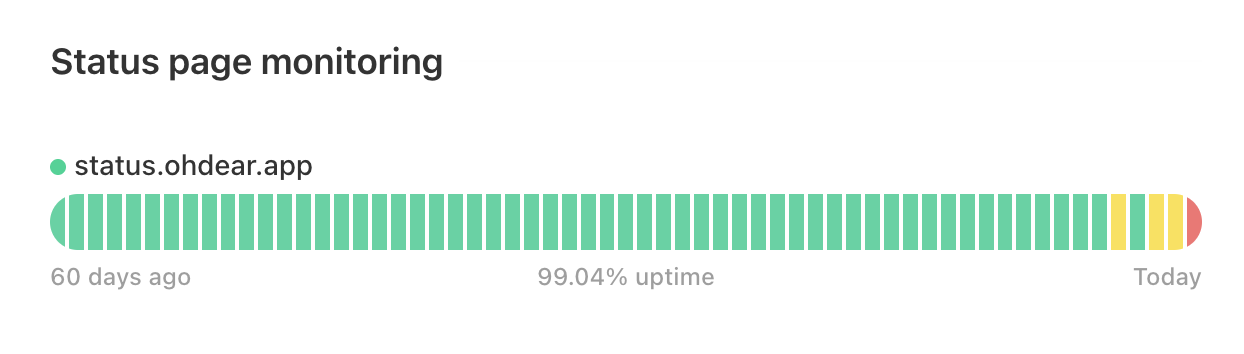
The uptime & availability of our status pages hasn't been great these past few days. The root cause is a persistent and pretty aggressive DDoS attack targeted at our own status page, status.ohdear.app. As a result, the overload on our systems also affected all other status pages we host for clients.
We're not yet at Github or Claude levels of uptime sadness, but this isn't acceptable to us. In this post, I'll share what's happening and what steps we've already taken.
The scale of the DDoS attack #
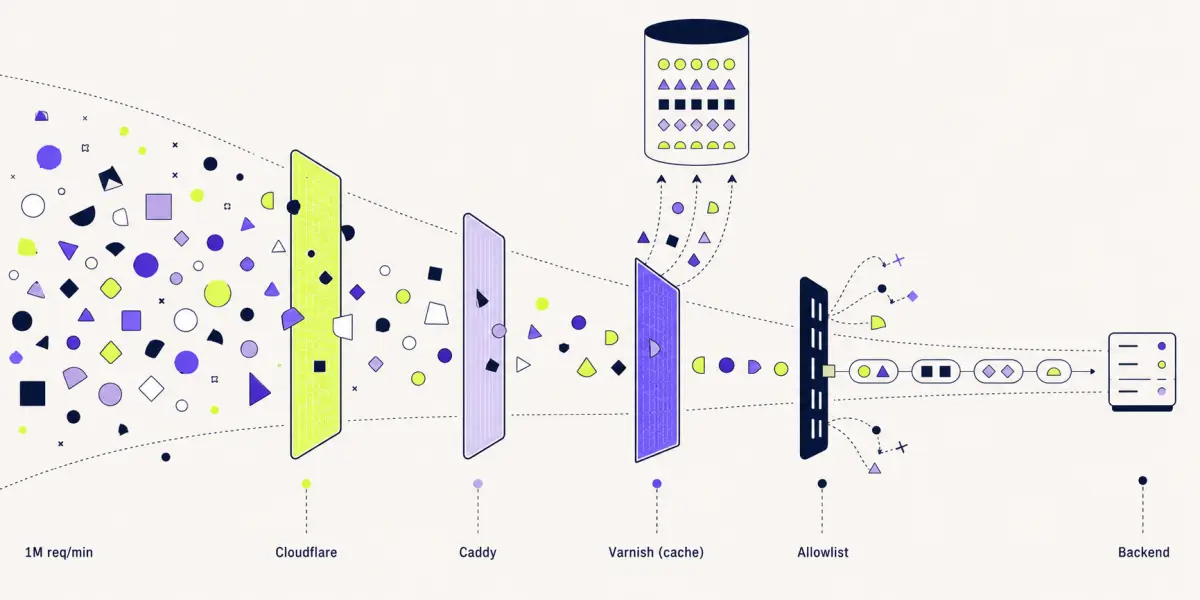
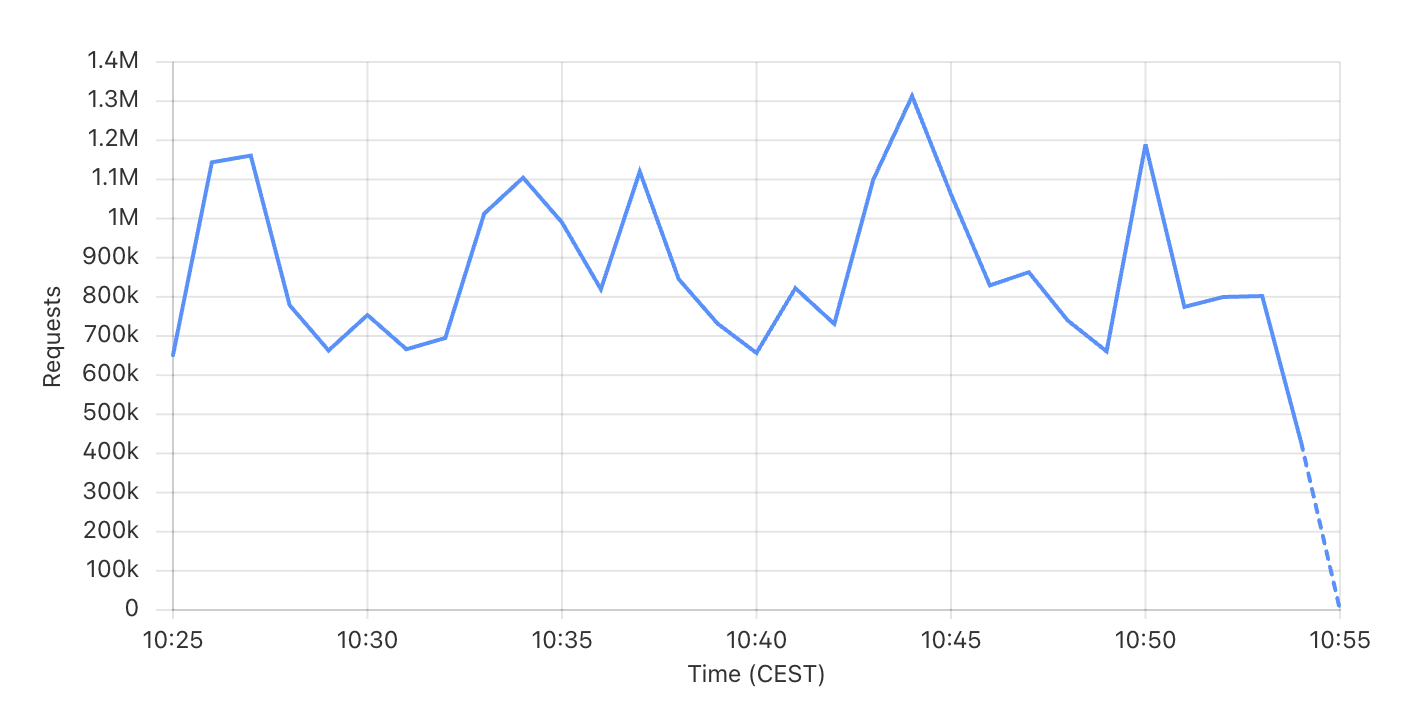
The attack varies in size, but is (still) generating roughly 1M requests per minute. That's about 16,000 requests per second hitting our status pages. The requests are for both legitimate & random URLs, some returning 200's and some 404's.
This certainly isn't a huge attack, but enough to throw our 100% uptime stats out the window.
We're the target, not our customers #
I'm not quite sure who we managed to offend, but the attack is directly targeting the Host: status.ohdear.app, our status pages.
This isn't an attack on any of our clients or their infrastructure - we've seen those too, but usually at smaller scale, and less persistent.
In this case, it meant we had the most flexibility to combat this attack: we control our domain, DNS and infrastructure. We only needed to synchronise internally on the measures, there wasn't any need for client communication to help resolve the issue.
Caddy overload, Cloudflare to the rescue #
Our status pages are served via Caddy running in our own infrastructure. Caddy handles the on-demand TLS to generate certificates for new domains that are starting to use our status pages. It's rock solid and has incredible throughput, but even our infrastructure has a limit on how many new TLS connections it can terminate a second, and we were hitting that ceiling pretty consistently.
With our CPU usage already upgraded and still pegged to 100% of capacity, we decided to offload TLS termination back to Cloudflare. We'd rather not do that for status pages: when Cloudflare had a long outage last year, our status pages remained up exactly because we didn't route that traffic over their network.
But drastic times call for slightly more drastic measures. With Cloudflare handling TLS termination and the CPU load that comes with it, the attack highlighted the next bottleneck: legitimate traffic overload.
Backend overload, Varnish to the rescue #
Our status pages proxy traffic back to our main infrastructure & serve the results to visitors. Even with Cloudflare handling TLS, that's still > 16,000 requests/second hitting our backend infrastructure.
To combat this, we installed and configured Varnish on the same status-page infrastructure that runs Caddy. I wouldn't recommend anyone try this as a "quick fix" solution, it comes with its own set of challenges and caching - as the saying goes - is hard.
But, having previously maintained the go-to templates for Varnish for versions 3, 4, 5 and 6, I feel pretty confident rolling this out in a hurry - understanding the gotchas.
Caddy, instead of proxying to our backend infrastructure, now proxies to Varnish - which caches the results in memory and only retrieves data from the backend when it doesn't have a cached version available.
Varnish will also serve slightly stale content, if our backend infrastructure is temporarily overloaded.
sub vcl_backend_response {
# Cache-Control: s-maxage=60 from the backend sets TTL automatically.
# Grace = how long we'll keep serving the stale object beyond TTL if
# the backend is slow or unhealthy. With grace=600s, a backend outage of
# up to 10 minutes is invisible to clients hitting cached status pages.
set beresp.grace = 600s;
# On backend 5xx, abandon the fetch instead of caching/delivering the
# error. The existing stale object stays in cache and keeps serving
# via grace until the backend recovers (or grace expires).
if (beresp.status >= 500) {
return (abandon);
}
}
Cloudflare also adheres to the Cache-Control headers, but only our domain is behind Cloudflare - all other clients are served directly by us, so Varnish mostly catches this issue for non-Cloudflare routed domains.
Random URLs, Varnish to the rescue (again) #
Caching is great, but all an attacker has to do is start randomizing URLs to completely bypass a cache. Even non-existent pages still cause load on our systems, so requests for status.ohdear.app/wp-admin/login.php won't work - we obviously don't run on WordPress - but they still pass through the routing layer & trigger a 404.
This problem we're solving in Varnish by allowlisting only certain URL patterns. We control our infrastructure & code, so we know exactly what URLs are valid and which ones aren't even worth bothering our backend for.
# Allowlist of URL shapes that status pages legitimately serve. Anything
# outside this set is 404'd at Varnish so noise (wp-login.php, .env probes,
# random crawlers) never reaches the PHP backend.
if (req.url !~ "^/(\?.*)?$" &&
req.url !~ "^/(json|xml|rss)(\?.*)?$" &&
req.url !~ "^/status-page/[a-z0-9-]+(/(json|xml|history|subscribe-slack(/create)?|subscribe-(rss|json|xml)))?(\?.*)?$" &&
req.url !~ "^/status-page-feed/[a-z0-9-]+(\?.*)?$" &&
req.url !~ "^/status-page-subscription/[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}(/delete)?(\?.*)?$" &&
req.url !~ "^/build/assets/[A-Za-z0-9._-]+\.(js|mjs|css|svg|woff2?|png|webp|jpe?g|gif|ico|map)(\?.*)?$" &&
req.url !~ "^/build/manifest\.json(\?.*)?$" &&
req.url !~ "^/favicon\.ico$") {
return (synth(404, "Not a status page route"));
}
Now, when someone tries to retrieve a page we know we'll never serve on our status pages, they just get a HTTP/2 404 back.
$ curl -i https://status.ohdear.app/wp-admin/login.php
HTTP/2 404
[...]
<!DOCTYPE html>
<html>
<head>
<title>404 Not a status page route</title>
</head>
[...]
</html>
This requires a bit of maintenance, but the public URL surface of our status pages is actually tiny, so the overhead to maintain this is negligible.
What doesn't kill us, makes us faster #
These changes have a positive effect on all our customers, too. Their status pages - now that Varnish sits in between - have all become substantially faster!
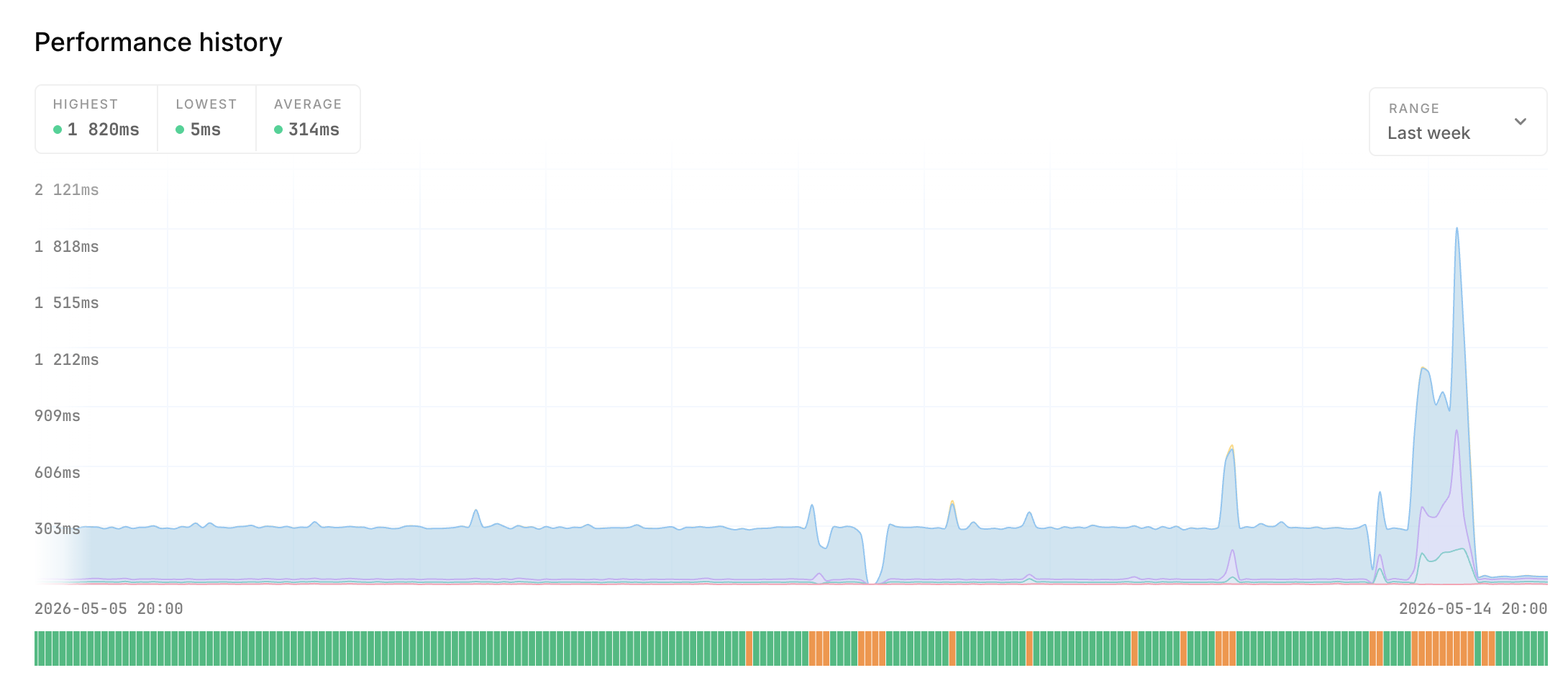
Before these changes, a status page would usually be served with a TTFB of around 250-300ms. Not slow, but also not exceptionally fast.
With these changes, we're serving status pages between 30-50ms now - fast enough to not even realize the page needed time to load, and resilient enough to weather the next attack with a lot more headroom.
What if it happens to a client status page? #
We've had the benefit of being able to easily slide a Cloudflare in front of the status pages, to help with offloading the CPU cycles related to TLS termination. We obviously can't just do that for a clients' status page, we don't own or control the DNS of those domain names.
In those cases, we'll reach out to the affected client(s) and work with them to resolve the problem, likely taking their status page offline for the time being. We can do this with an SNI-based filter that drops connections targeting their domain before the TLS handshake completes - the SNI (Server Name Indication) is sent in the TLS ClientHello in plaintext, so we can inspect it without spending CPU on crypto. Tooling-wise, that's either caddy-l4 compiled into our Caddy binary, or HAProxy in TCP mode sitting in front. Both let us block a single customer's hostname surgically without affecting anyone else.
Not great, we know - and we welcome any other solutions to this problem - but we serve status pages to thousands of customers, and in this case the needs of the many outweigh those of the few. Longer term, we're looking at offering a CNAME-able Cloudflare-fronted endpoint for customers who want it, so their custom domain inherits the same DDoS protection without them needing a Cloudflare account.