The ghost domain problem in DNS, and what we're doing about it
Published on June 2, 2026 by Mattias Geniar

There's a DNS edge case that even people who know DNS well tend not to have run into: a domain pulled by its registry can keep appearing healthy to uptime checkers for days after it's gone. The .de zone triggers it when contact verification fails, and other registries have their own versions. We don't always catch it, and most other monitoring services don't either.
It's called the ghost domain problem. It's documented in DNS research circles and has an active IETF draft (draft-ietf-dnsop-ns-revalidation), but it's niche enough that an uptime product can run for years without anyone noticing it. This post is about why, and the small set of changes we're making on our end.
How it shows up #
The .de zone has a strict holder-data verification policy. If the registrant's details aren't verified within DENIC's deadline, DENIC first removes the domain from the .de zone and deletes it later. And .de is far from alone. EURid suspends a .eu domain and, if the data still isn't verified, moves it to a withdrawn (no longer registered) state. AFNIC runs an eligibility and contactability check on .fr holders and can suspend, then eventually delete, a domain whose holder doesn't correct or substantiate their data.
And across ICANN gTLDs like .com, .net, and .org, the 2013 WHOIS Accuracy Program requires the registrar (not the registry) to suspend, terminate, or place a domain on clientHold after more than 15 days without a response to a verification request, which pulls it from zone publication. Failed verification, expired registration, registrar disputes, abuse takedowns: the names differ, the shape doesn't. The registry or registrar pulls the name from the parent zone, but the domain's own authoritative nameservers keep answering as if nothing changed.
For anyone whose resolver no longer holds the child-side records, that means NXDOMAIN (RCODE 3, "name does not exist"). A fat error in the address bar, no site. For an uptime checker sitting behind a long-lived recursive resolver cache that does still hold them, it can mean nothing at all. The difference isn't browser versus checker, it's a cold cache versus a warm one. The site looks fine. It isn't.
Where the bug lives #
This was the DNS chain we had on one of our uptime workers (Frankfurt, in this case):
PHP/curl → glibc nsswitch (files dns) → /etc/resolv.conf (127.0.0.53) → systemd-resolved stub → upstream recursive resolver (shared, run by the hosting provider) → authoritative nameservers (the domain's DNS provider)
I'll spare you the full diagnostic. The summary: systemd-resolved is a local caching stub. The real resolution work happens in a recursive resolver upstream, and that's where the bug lives. Not on our box, and not on yours. This is inherent to how recursive DNS works, no matter who runs the resolver: the caching layer that makes DNS fast is the same layer that can keep a dead delegation warm.
That detail matters. We could ship the most diligent uptime checker on the planet and still get the wrong answer, because we're trusting a cache we don't control.
Ghost domains, briefly #
The mechanism is documented in academic literature (the NDSS Ghost Domain Names paper from 2012, and a 2023 follow-up Ghost Domain Reloaded). It currently sits in an active IETF draft, Delegation Revalidation by DNS Resolvers. The credibility rule it depends on is in RFC 2181, and the delegation-versus-glue terminology in RFC 9499 (which obsoleted RFC 8499).
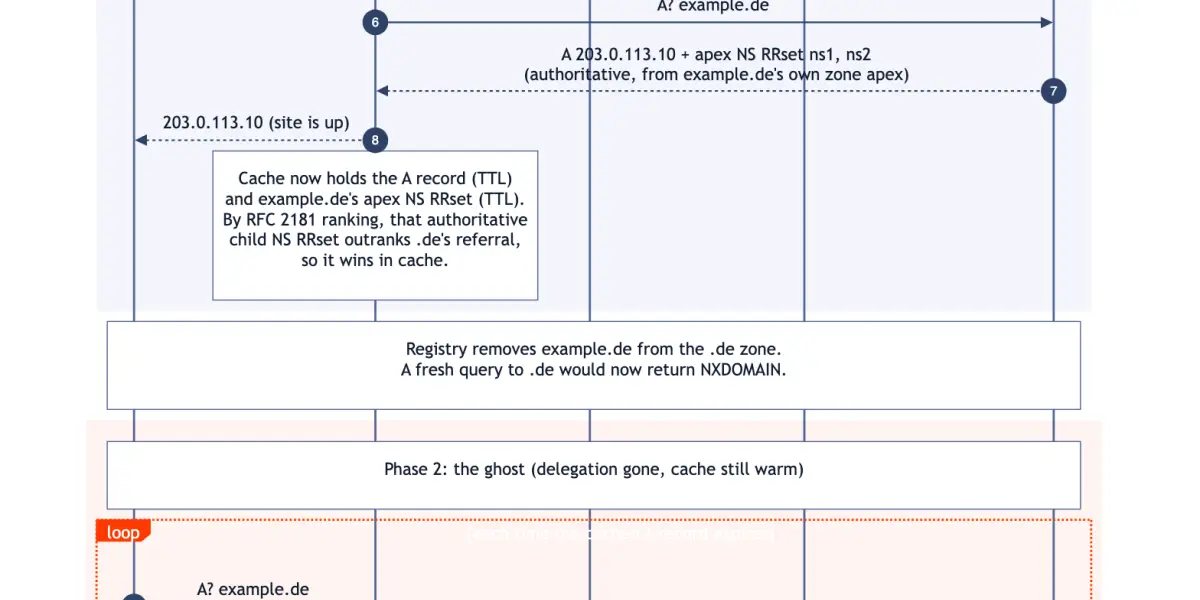
Here's how it plays out, step by step:
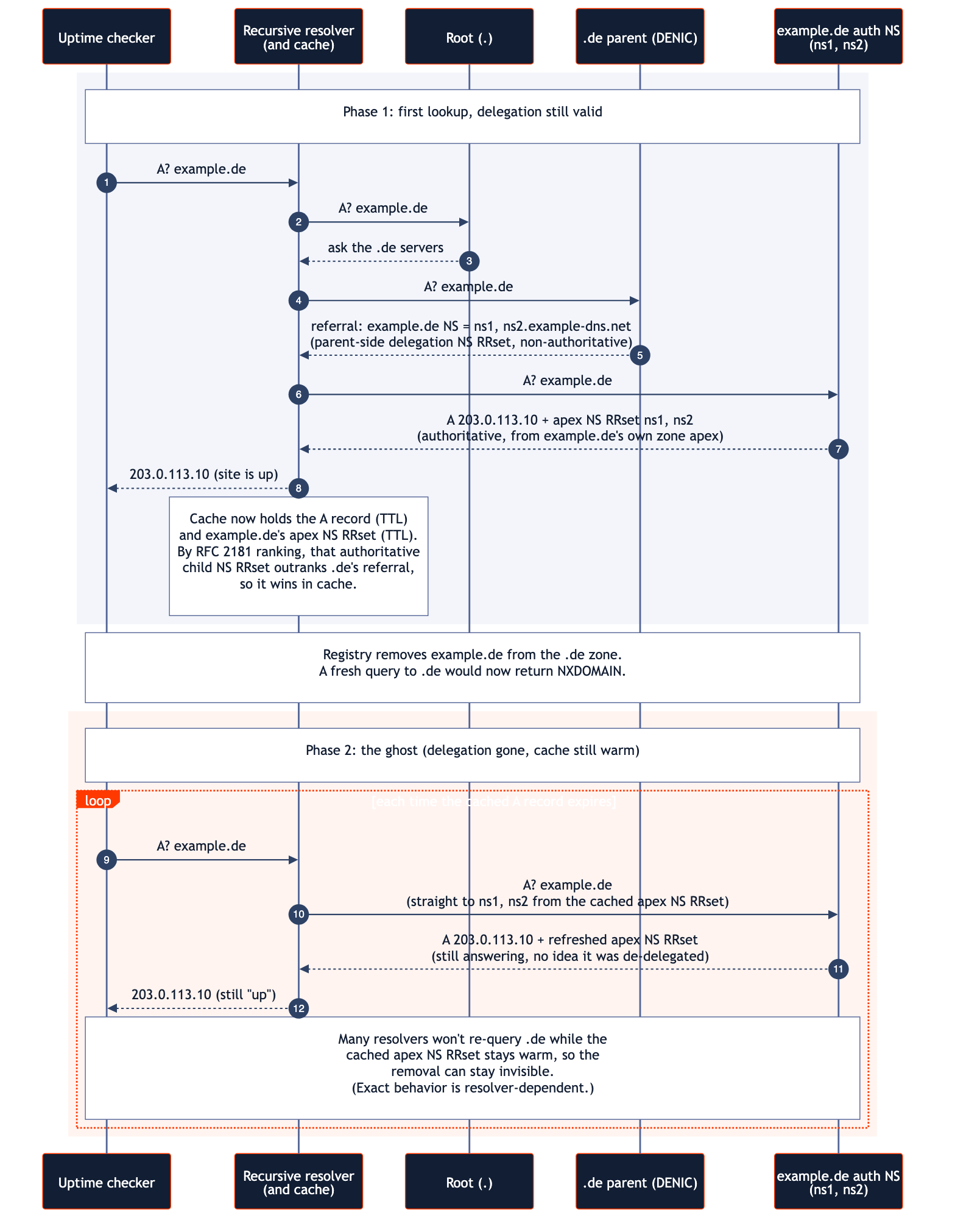
Step 1: The first lookup
The first time a recursive resolver looks up example.de, it walks down to the .de (parent) servers, which hand back a referral: "I don't host example.de, but its nameservers are ns1.example-dns.net and ns2.example-dns.net." That's the parent-side delegation NS RRset, the NS records for example.de, as published by .de.
The resolver then asks those nameservers directly, and their authoritative answer usually carries the same two-name list again, this time published by example.de itself from its own zone apex. That copy is the apex NS RRset. Auth servers aren't required to include it, but they usually do, and the ghost effect depends on it being cached.
Step 2: The child's copy outranks the parent's
Both RRsets name the same two servers; the difference is who said so. Per RFC 2181's ranking rules, the child's authoritative apex copy (from example.de) outranks the parent's referral copy (from .de), so it replaces the parent-side one in cache. To be clear, this is the NS RRset for example.de itself, not the NS records of the .de zone.
Step 3: The A record expires
Later, when the A record expires, the resolver asks "where do I find example.de?", finds the cached apex NS RRset (still pointing at ns1 and ns2.example-dns.net), and queries those nameservers directly.
Step 4: The authoritative servers still answer
The authoritative nameservers still answer positively. They have no idea the registry pulled the delegation. Why would they?
Step 5: The loop
A fresh A record gets cached. Another TTL window starts. Loop.
Absent any revalidation, the parent zone is ordinarily not consulted again as long as the apex NS RRset stays warm. And the defaults don't help:
| Resolver | Cache window | Parent revalidation |
|---|---|---|
| BIND | max-cache-ttl = 1 week |
No equivalent delegation-revalidation control |
| Unbound | cache-max-ttl = 1 day |
harden-referral-path off by default |
| PowerDNS Recursor | max-cache-ttl = 1 day |
save-parent-ns-set (a failure fallback, not revalidation) |
| systemd-resolved | caching stub, inherits upstream | n/a |
It's tempting to assume frequent uptime checks are what keep the cache hot. Not quite. What keeps a ghost alive is the resolver reacquiring the apex NS RRset before it ages out, and how long that RRset lives is bounded by its own TTL and the resolver's cap. Check frequency only matters as opportunities to reacquire it, so cutting back on checks won't save you: a domain with a long NS TTL can keep ghosting off very few lookups per cache window.
What every other monitoring service does #
I went looking. I read the public docs, FAQs, and architecture pages of Pingdom, UptimeRobot, StatusCake, Site24x7, Datadog Synthetics, and Better Stack.
I couldn't find a documented defense against this in any of their public materials.
Pingdom actually documents the architecture that causes the bug, in their own blog post:
Each of Pingdom's probe servers run their own individual Bind9 caching DNS server as their DNS resolver, so DNS records will be cached.
We don't know how they've tuned it, and a per-probe BIND is a perfectly reasonable setup. But BIND's default max-cache-ttl is one week, and unless that's been lowered, it's exactly the kind of cache horizon where a ghost domain can stick around for days.
A few of these tools monitor domain expiry, and so do we: Oh Dear has domain expiration monitoring that warns you well before a renewal date slips past. But that's adjacent, not the same thing. Expiry monitoring watches the registration date, not whether a still-paid-for domain has been pulled from the zone over a failed verification. I couldn't find any tool, ours included, that treats registry-level delegation removal as a distinct case in its uptime checks.
This isn't a gotcha against any of them. It stayed off our radar for the same reason it probably has for theirs: it's a DNS-layer problem hiding under an HTTP-layer product, invisible until someone goes looking.
What we're tightening #
We're keeping this narrow.
A local recursive resolver on each checker, with a tight cache. We're running Unbound on each worker, doing full recursion itself instead of forwarding to a shared upstream resolver. The point isn't "ours is better." It's that we get to set the knobs.
Two of them matter here:
| Knob | Default | Our setting | Why |
|---|---|---|---|
cache-max-ttl |
1 day | 1 hour | Caps how long a stale apex NS RRset can ghost a domain |
harden-referral-path |
off | on | Re-checks NS data along the referral path, not just cache |
Unbound caps cached records at a day by default; we clamp that to an hour. Once the cached apex NS RRset expires, the next lookup has to restart iteration from the closest cached cut, typically the TLD's nameservers, to find the delegation again, and that's exactly where a pulled delegation now comes up empty. harden-referral-path (paired with a deeper target-fetch-policy, as the Unbound docs recommend) makes the resolver re-check the NS data it meets on the way down instead of trusting stale child-side state.
That's the main change. It doesn't make ghost domains impossible, but it shortens the window in which a stale delegation can lie to us from days down to about an hour.
We've thought about heavier options. Cross-resolver verification on failed checks, where we'd cross-check with 1.1.1.1, 8.8.8.8, and 9.9.9.9 in parallel. Dedicated parent-zone delegation polling per monitored domain, à la dig @f.nic.de example.de NS. Both are real fixes, and we may come back to them. But the operational cost (extra DNS load, public resolver rate limits) is hard to justify when tightening our own resolver already covers the realistic cases.
What this doesn't fix #
DNS caches exist for good reasons. The whole reason a recursive resolver works the way it does is to keep the global DNS from melting every time someone reloads a page. We're not going to "fix DNS." What we can do is narrow the window where a stale delegation goes unnoticed.
If a ghost domain's apex NS RRset keeps refreshing inside our shorter cache window, it can still slip past us. Other layers (the registry's own propagation cadence, the authoritative DNS host, the resolvers downstream from us) all behave their own way. We're reducing surface area, not eliminating it.
And we're honest about the tools we reached for. harden-referral-path is experimental and not an RFC standard, so we run DNSSEC validation alongside it in permissive, log-only mode: bogus answers get logged for us to review, not turned into SERVFAIL, so a signing glitch on a customer's domain can't show up as false downtime. That's a deliberate first step. Once the logs stay clean and the rollout proves stable, we plan to flip DNSSEC to enforcing over the coming weeks.
What you should do #
If you run anything important on a domain you don't own at the registrar level, run DNS monitoring alongside uptime monitoring. Uptime monitoring answers "can my site be reached?" DNS monitoring answers "is the DNS layer healthy?" Together they catch problems neither one would on its own.
In Oh Dear, you turn DNS monitoring on per monitor in the DNS check settings. It watches your A, AAAA, MX, NS, and TXT records and alerts when they drift. It's part of your plan, not a paid add-on: every monitoring check we offer is included, at no extra cost.
If you're not an Oh Dear customer yet, you can try it for 10 days, free, no credit card needed. And if you hit a monitoring edge case we don't catch yet, show us. We'll make Oh Dear better by building the fix in.